■ はじめに
https://dk521123.hatenablog.com/entry/2023/03/04/222610
の続き。 今回は、Snowflakeのパフォーマンスのキーとなる 「プルーニング」、「マイクロパーティション」、「スピル」 について扱う
目次
【1】プルーニング(Pruning) 1)どうやって確認するのか? 【2】マイクロパーティション(Micro-partition) 1)データ構造 2)特徴 3)利点 4)クラスタリングの深さとの関係 5)クラスタリングの深さの確認方法 【3】スピル(Spill) 1)スピル対策
【1】プルーニング(Pruning)
https://docs.snowflake.com/ja/user-guide/tables-clustering-micropartitions#query-pruning
* クエリ実行時に、不要とわかっているパーティションを読みに行かない => ストレージIOを減らし、パフォーマンスを向上してくれる => プルーニングが出来れば出来るほど良いことになる => ★この「プルーニング」がキモになる cf. Pruning = 枝刈り、間引き、剪定(せんてい)
1)どうやって確認するのか?
クエリプロファイルの統計欄に、 テーブル全体のパーティション数「パーティションの合計(Partitions total)」に対し、 実際にアクセスしたパーティション数 「スキャン済みパーティション(Partitions scanned)」が小さければ小さい程、 プルーニングが効果的に行われたことになる => 詳細は、以下の関連記事を参照のこと
Snowflakeのパフォーマンス改善 ~ クエリプロファイル / 実行計画 ~
https://dk521123.hatenablog.com/entry/2023/09/12/194705
【2】マイクロパーティション(Micro-partition)
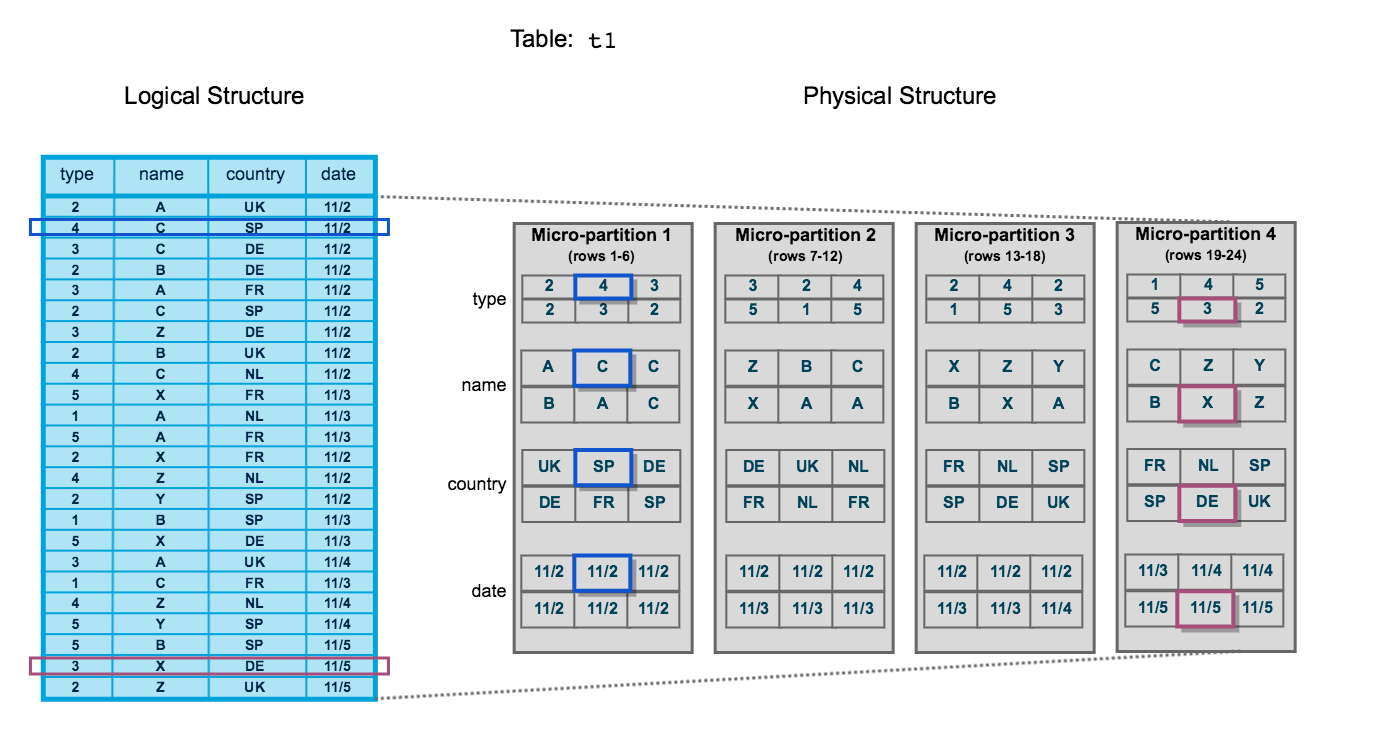
* Snowflake では、デフォルトで「マイクロパーティション」という ストレージ単位で自動的にデータ分割される => 自体は、小規模なファイル群 => Snowflake の特徴のひとつ
https://docs.snowflake.com/ja/user-guide/tables-clustering-micropartitions#what-are-micro-partitions
1)データ構造
* まずは、公式サイトの以下の図が分かりやすいかも。 => ただし、実際のデータ構造ではない => Snowflakeがマイクロパーティションで使用する データクラスタリングの小規模な概念的表現としてのみ意図した図
https://docs.snowflake.com/ja/_images/tables-clustered1.png
https://docs.snowflake.com/ja/user-guide/tables-clustering-micropartitions#what-is-data-clustering
{kind=link}
* マイクロパーティションの分割単位は、「行」 * マイクロパーティションの内部では、「列」ごとにデータがまとめて圧縮
2)特徴
* マイクロパーティション1個の容量は、圧縮ファイルで約16MB * 列指向ストレージ * 不変(immutable)
3)利点
[1] Hiveのような従来なパーティションと違って Snowflake内で自動的に行われる [2] 非常に効率的な DML および きめ細かいプルーニングにより、 クエリを高速化してくれる [3] 値の範囲内で重複する可能性があり、 均一に小さいサイズと組み合わせて、 スキュー(Skew;データの偏り)を防ぐ [4] 列指向により列のみを効率的にスキャン [5] Snowflakeは、各マイクロパーティションの列に対して 最も効率的な圧縮アルゴリズムを自動的に決定
4)クラスタリングの深さとの関係
平均クラスタリング深度(Clustering Average Depth)とは?
* どの程度マイクロパーティションが オーバーラップ(一部の範囲のみ重なる)しているかを図る指標 => 理想的なマイクロパーティション状態としては、 他のマイクロパーティションとオーバーラップしていない状態が良い => 1以上の数値で、この値が大きいほど理想状態から離れていることになる
理想としては
[1] マイクロパーティションの重複(Overlapping micro-petitions)が少ない程 マイクロパーティションを読む数が減る(=プルーニングが効く)ので パフォーマンス向上する [2] 重なり合うマイクロパーティションの数が減少すると、 マイクロパーティションの重なりの深さ(Overlap depth)が現象するので 深さが少ない程良いことになる。
5)クラスタリングの深さの確認方法
https://docs.snowflake.com/ja/sql-reference/functions/system_clustering_information
* SYSTEM$CLUSTERING_INFORMATION によって確認できる => 詳細は、以下の関連記事を参照のこと
https://dk521123.hatenablog.com/entry/2023/03/04/222610
構文
SYSTEM$CLUSTERING_INFORMATION( '<table_name>' [ , '( <expr1> [ , <expr2> ... ] )' ] )
【3】スピル(Spill)
Snowflake ではメモリで処理できなくなったら、 データをローカルディスクに保持し、 さらにデータが増幅して溢れると、リモートストレージに保持される => この「溢れる」ことを、「スピル」という => この「スピル」は、起これば起こる程、パフォーマンス劣化する cf. Spill = こぼす、あふれさせる、ばらまく、
https://docs.snowflake.com/ja/user-guide/performance-query-warehouse-memory
1)スピル対策
[1] ウェアハウスのサイズを増やす
* ウェアハウスのサイズがデカければ、 ローカルディスク容量も大きいので、スピル防止になる => 値段は上がるが、一時しのぎであれば、1つの手
[2] Spill が発生している操作に入力されるデータ量・行数を減らす
* 先出しできる集約を先出しする * WHERE 句の条件を追加・変更する * 不要なカラム・テーブルをクエリから削除する * select * より、select [項目] でできる限り絞る => (DBと違い?)Snowflakeを始め、列志向型は、SELECTの項目を絞ることにより メモリ消費を抑えられる => Tipsとして、SELECT文のEXCLUDE により除外する方法もあり => SELECT ... EXCLUDE については、以下の関連記事を参照のこと
Snowflake ~ SELECT ... EXCLUDE ~
https://dk521123.hatenablog.com/entry/2024/10/01/195225
参考文献
スピル
https://qiita.com/foursue/items/7e818ab2b5cbedb8e092
https://zenn.dev/indigo13love/articles/b93ab72f34aa72#spill
関連記事
Snowflake ~ 基礎知識編 ~
https://dk521123.hatenablog.com/entry/2021/11/02/130111
Snowflake ~ 入門編 / Hello world ~
https://dk521123.hatenablog.com/entry/2021/11/22/212520
Snowflake ~ 基本編 / アクセス制御 ~
https://dk521123.hatenablog.com/entry/2021/11/16/231010
Snowflake ~ SELECT ... EXCLUDE ~
https://dk521123.hatenablog.com/entry/2024/10/01/195225
Snowflakeのパフォーマンス改善 ~ クラスタリングキー ~
https://dk521123.hatenablog.com/entry/2023/03/04/222610
Snowflakeのパフォーマンス改善 ~ クエリプロファイル / 実行計画 ~
https://dk521123.hatenablog.com/entry/2023/09/12/194705
Snowflakeのパフォーマンス改善 ~ データロードの改善 ~
https://dk521123.hatenablog.com/entry/2022/12/07/111847
Snowflakeのパフォーマンス改善 ~ 検索最適化サービス ~
https://dk521123.hatenablog.com/entry/2023/02/27/120943